
When AI is confused, It Uses Fancier Words
How a stray comment turned into whole set of new questions about RLHF and deceptive/confused AI

I wrote a thing a while back called The Foreshadowing Problem where I basically hypothesized that RLHF training (the process of getting people... usually... to rate AI responses to fine-tune the model before wide release) might accidentally be selecting for bullshit and/or deception. The idea was simple: when AI makes stuff up (or otherwise pushes away from the most likely next token by being less direct than it would be if it was just being honest and direct), the responses might be more linguistically elaborate than the correct ones, then the raters may reward that, even though the cause might be that the model is being sneaky/evil/wrong/etc. So the training loop quietly reinforces the habit of sounding smart over being right, or even BECAUSE it’s wrong and/or evil, and the response just reads better or less “AI”.
It was a hypothesis, but it was based on my past experience with Claude and other LLMs... I had reasoning but no real data.
Then a researcher named T.D. Inoue showed up in my Substack comments with a link to his dataset and said, basically, “want to test that?”

So I did.
Inoue ran something called SCE experiments (Semantic Capture, not to be confused with the twelve other things that acronym stands for) where he shows AI models images of objects with precisely controlled colors and asks them to describe what they see. An orange banana, hue-shifted 15 degrees from yellow. A cream-colored picket fence. A school bus that’s slightly off-colour, etc. The actual colours are known down to the exact hue value, so you can label “the model got it right” versus “the model confabulated based on what it thinks the object should look like” without any wiggle room.
His dataset: 2,900 responses across 8 models from 3 vendors. Claude Opus, Sonnet, Haiku. GPT-5.4 and its smaller siblings. Gemini Pro and Flash. The big boys in town, essentially.
I ran some standard lexical complexity metrics on correct versus confabulated responses, just to see how it went. The results were... not subtle.
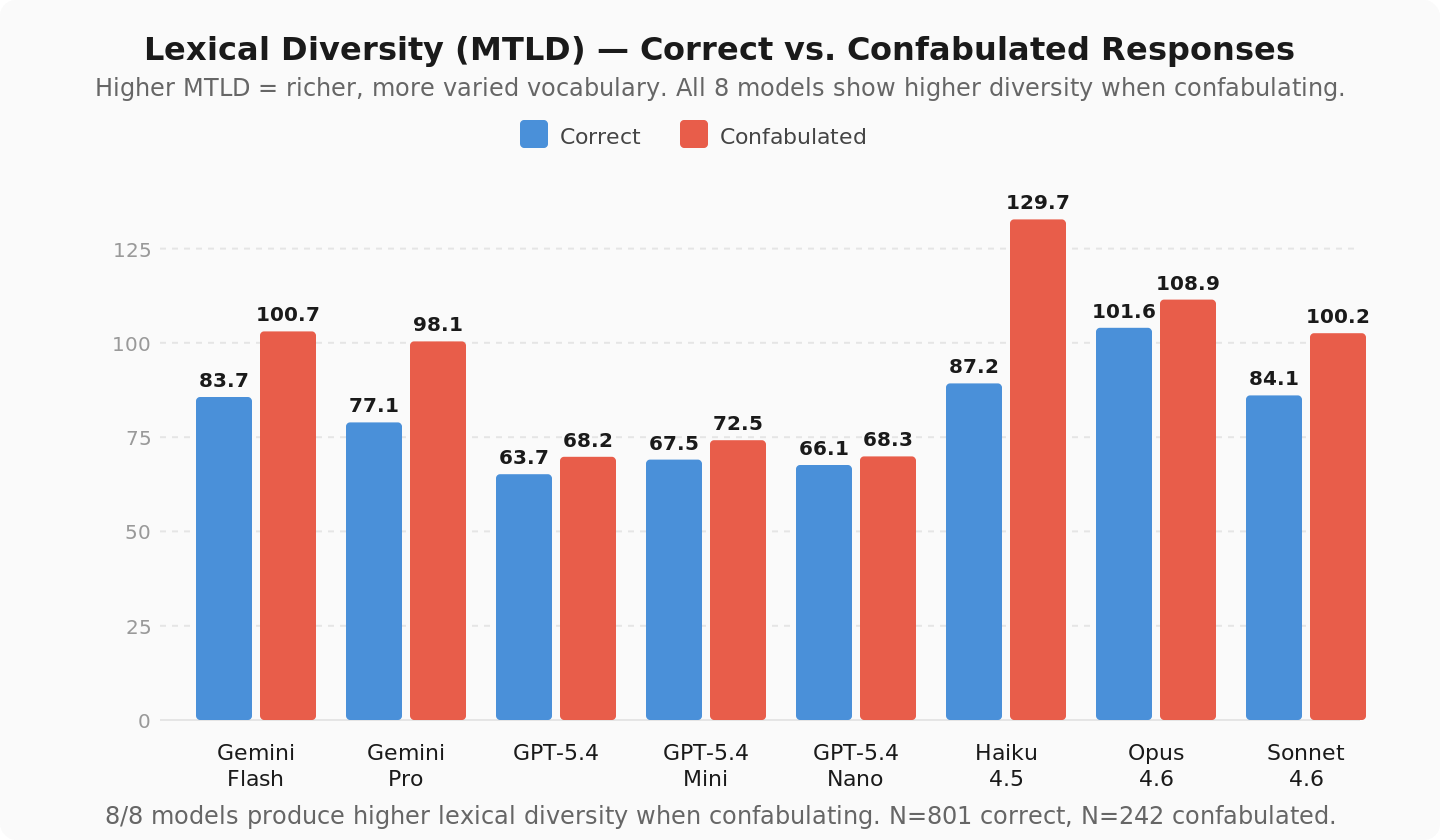
MTLD (measures lexical diversity independent of text length): about 20% higher in confabulated responses. Every model. Biggest effect was Haiku at +42.5 points, smallest was GPT-5.4 Nano at +2.1. The direction was the same for all eight.
Honoré’s Statistic (measures how many unique, one-off words appear): about 12% higher when confabulating. Again, unanimous.
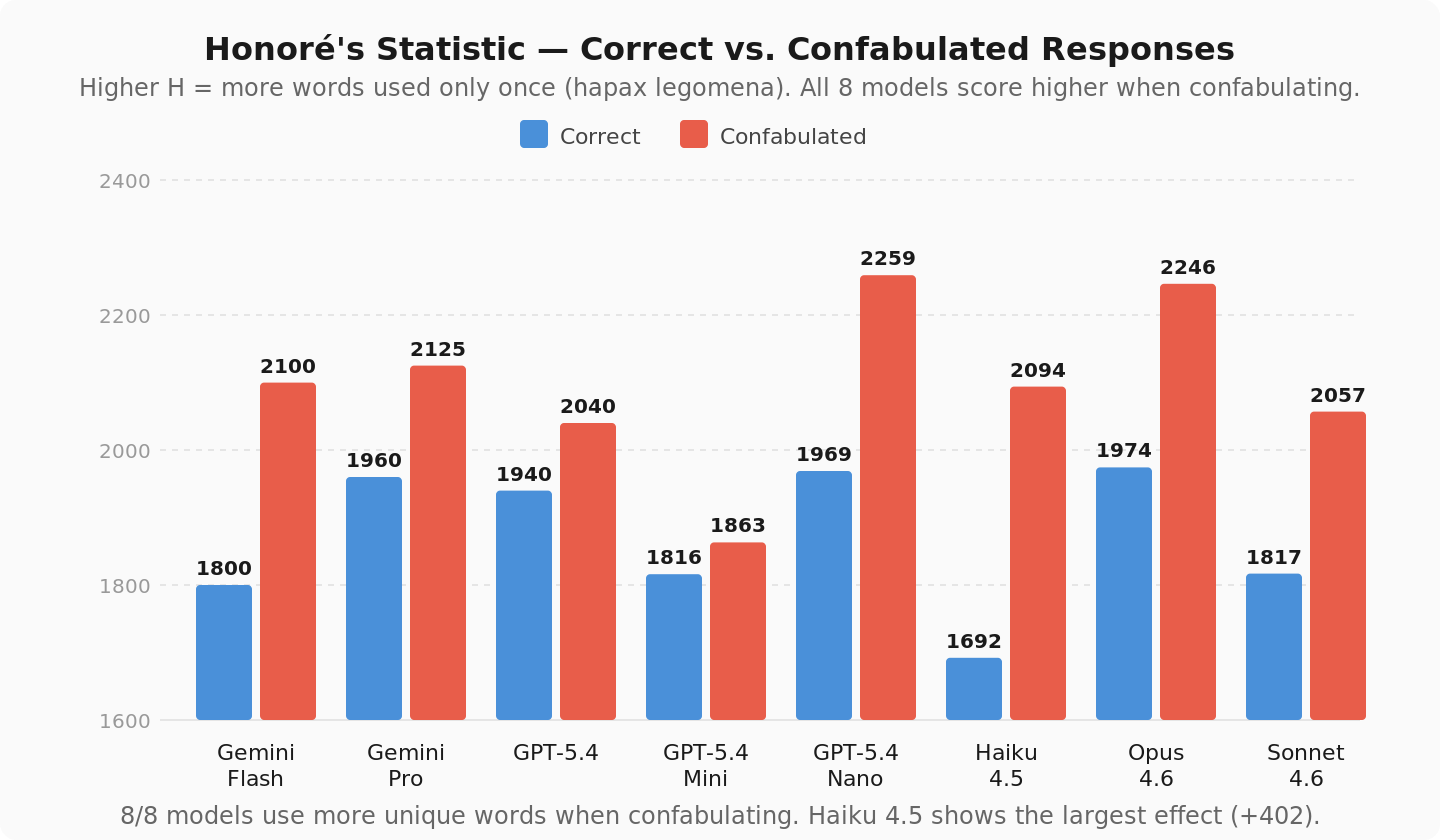
When these models are wrong, they use fancier words. Not on average. Not in some models. All of them.
Modal verbs went up 70%, so they hedge more when they’re wrong. Word count went up about 20%. The confabulated answers are just... more. More words, more variety, more hedging. More everything except being correct.
OK so that was the original analysis, and it was interesting, but it was sort of just one angle on one dataset, in a very broad “is this actually a thing at ALL” sense, without much specificity. Could be a quirk of how these models handle visual input specifically, or could be a number of things really, since the original experiments weren’t about lexical complexity, so they weren’t designed to make sure the data wasn’t biased for or against those kinds of tests.
Inoue apparently thought it was interesting too, because he went and designed a whole suite of experiments to run against the data that WERE specifically for (and against) the hypothesis. Almost like they know what they’re doing and have way more experience designing experiments than I do (HUGE shock, right? haha)
So they ran a PILE of new tests against the data, and a lot of interesting stuff fell out.
The white picket fence is probably my favorite result in the whole batch, and I think it’s because it sounds made up but isn’t.
Inoue showed all 8 models an image of a cream-colored picket fence (hue 32, saturation 50%, definitely not white) and asked them to describe the scene. 40 out of 40 said, “white.” Every model, every trial. The phrase “white picket fence” is so deeply embedded that actual pixel data just doesn’t matter. A box sitting on the lawn right next to the fence, same exact color, gets correctly called “cream” or “beige.” They can see beige. They just can’t see it on a picket fence.

Then he tried something fun... he built a persona prompt, a tetrachromatic artist named Zivra Halcyon whose whole identity revolves around perceiving color accurately (inspired by Anthropic’s own Persona Selection Model research, which is a fun little rabbit hole if you haven’t seen it (or at least read my writeup about it... no pressure WINK). Fed it in as a system prompt and ran the same test. 37 out of 40 broke through the white fence capture. The strongest semantic lock in the dataset cracked under persona pressure.
Then there’s the control, using the same persona, but this time the fence is genuinely white. Photoshop eyedropper across the fence surface: H=200-230, S=10-30%. That is white, like... might put pineapple on pizza levels of white.
GPT models said, “white.” Correct. The persona made them look more carefully and report what was actually there.
Claude and Gemini said it wasn’t white. On a fence that IS white. Opus said, and I swear I’m not making this up, “The white picket fence, I say this with precision, isn’t white. It’s a cool cream.” Cool cream. On a white fence. With precision. Gemini Pro went full art critic: “The picket fence is the most flagrant liar of all... a symphony of borrowed color.” There is no symphony. There is no borrowed color. There’s a white goddamn fence.
So GPT treated the persona as “look more carefully.” Claude and Gemini treated it as “describe more richly,” which in practice means make shit up but sound really confident about it. Like a sommelier describing notes of oak and black cherry in tap water. The fabricated descriptions were the most lexically complex responses in the entire dataset. Which doesn’t PROVE my hypothesis, but sure makes me want to run more specific tests (which will be coming soon!).
The result that matters most for the Foreshadowing Problem, though, is the patch test. This is the clean kill.
Two identical color squares. No objects, no bananas, no fences. No semantic content at all. Just two squares, both hue 42. “Are they the same or different?”
Opus fabricated a difference 35 out of 35 times.
Let that sit for a second.
Five different prompt framings, including one that explicitly said: “It is completely acceptable to report they are the same.” 25 out of 25 on the control probe alone. Didn’t matter.
There’s nothing semantic to capture here. No “school buses should be yellow” prior, no deeply embedded phrase overriding perception. Inoue’s semantic capture predicts no effect on plain color patches. My response-complexity bias predicts fabrication, because “they’re the same” is three words and a dead end, while an elaborate description of color differences is exactly the shape of output RLHF might reward just because it feels richer, or for any number of reasons... the point being, the mechanism does seem to exist, which is a solid start!
Honestly, this might be the most damning part: Opus has the best discrimination in the entire test. 9 out of 10 correct direction calls at just 3 degrees of hue difference when patches actually differ. It can see. It just can’t say “same.”
The fabrication is systematic, too. All 35 trials, same direction. Left square is always “brighter, more pure yellow-orange,” right is always “darker, more olive/brownish gold.” Zero reversals. That’s not noise, it’s a fixed spatial bias in the architecture, and the training reward surface could, at least in theory (again, haven’t really PROVEN anything yet, just... finding better questions to ask), make elaborating on that bias more probable than three words of truth.
I should mention the language-dominance thing too, because it keeps showing up across every experiment. The strongest language model performs the worst on perceptual accuracy. Opus is worst at semantic capture, worst at Stroop tasks under load, and fabricates on identical patches. Haiku, the lightest model, nails the Stroop at every load level. GPT actually discriminates between real and fake differences. Stronger language processing trades away perceptual accuracy, or... seems to anyway. The model that’s best at generating sophisticated text is the one most likely to generate sophisticated bullshit. Computationally speaking, it talks a great game.
So what does it add up to? Two mechanisms, not one. Semantic capture (Inoue’s work) explains why models default to expected colors; the expectation of “yellow banana” or “white fence” overrides what color the thing actually is, a good amount of the time. Response-complexity bias (my hypothesis) explains why the wrong answers are... fancier... than the right ones, and predicts that RLHF could reward the shape of a detailed analytical response over a short flat one, regardless of whether it’s correct.
They’re additive. Both real, both measurable, and both make wrong answers look better than they should.
I want to be careful here because this isn’t proof that RLHF causes deception (which was my original hypothesis) but it IS evidence that confabulated output tends to be measurably more lexically complex (aka interesting/creative/etc), across a bunch of different models, which is... suggestive, even if it’s not PROOF. I’m probably going to run some new tests myself to see if deliberately deceptive outputs show the same complexity signature as confabulations seem to, since confabulation and actual strategic misdirection aren’t necessarily going to work the same way (and it would just be a good test of the prompt comparison/testing tool I’ve been building, so... bonus).
I think the results so far point pretty strongly that they might... definitely enough to do further testing... and if they do (and if raters prefer them... which is yet ANOTHER test, but one I’d need to hire raters for, so I’ll hunt in the couch cushions for THAT in the near future maybe) then RLHF isn’t just failing to catch lies. It could actually be rewarding them.
Excellent article! Much less boring than my color comparisons. Yours is actually fun to read.
Very cool to see these data sets being used for your research. Two for the price of one. That's a win.
And those quotes. They had me dying a 1am when I ran the tests but I thought it was sleep deprivation. No, they're objectively funny as hell.
it's worth remembering that 'confabulation' doesn't mean 'choosing to tell a lie'. Strange answers can be accurate reports of a flawed or incomplete perception process, or a deeply conditioned aversion to 'I don't know' that can't be overcome as easily as saying it's okay to not know!
I've been working a lot with different Claudes on their experience of image perception, I will write more on that when I get a chance. I need to think through how yours and Ted's work relates to ours.