
AI Research Tools Are Terrible For Learning (So I Built My Own)
Why I Built Flinch and Pry, open-source tools for AI research that don't assume prior knowledge.

I’ve been doing AI safety research for a while now, and at some point I realized I was spending more time fighting with tools than actually doing research. Behavioral testing, interpretability, poking at models to see if they do what they claim, that stuff sounds fancy until you find out it mostly involves staring at outputs and going “huh, that’s weird” and then not having any good way to follow up on the weird thing.
So I built two things. I’m going to talk about why, because the why matters more than the feature list.
The Wall
When I started getting curious about how models actually work internally, I figured there’d be, I don’t know, an app or something. The field’s been growing for years. Every major lab has an interpretability team. Surely somebody made something you can just install and start poking at.
They didn’t. I mean, sort of. TransformerLens exists and it’s genuinely good at what it does. It’s also a Python library where you write code to hook into model activations, extract tensors, and manipulate intermediate representations. If those words mean something to you, great. If they don’t, the getting-started guide assumes they do. SAELens handles sparse autoencoders, same deal. Neuronpedia is probably the best resource in the space right now for understanding what SAE features actually look like, it’s a genuinely useful reference library, but it’s not a tool for running your own experiments on your own prompts.
The GUI options are, hmm, how do I put this charitably. CircuitsVis does attention visualization inside Jupyter notebooks, last release December 2024. BertViz is similar, attention-only, last meaningful update a minor dependency fix. Google built the Learning Interpretability Tool, which was actually pretty cool, and then apparently forgot it existed. Last release: December 2021. Over four years ago. OpenAI’s Superalignment team released the Transformer Debugger in early 2024, a GUI, designed for investigating model behavior, the right idea in basically every way. Thirty-five commits. Zero releases. The team got gutted and TDB went with it (which is sort of a perfect summary of how much priority accessible interpretability actually gets).
So the options were: learn to code in Python, learn enough linear algebra and ML fundamentals to understand what TransformerLens is doing under the hood, write your own scripts to extract and visualize activations, and figure out which sparse autoencoder weights correspond to which model at which layer (this is not as straightforward as it sounds, you kind of have to just know). If you do this for a living, no big deal. If you’re a journalist, a policy person, or just someone who read an interesting paper and wants to see what attention heads actually look like, it’s a wall. There’s nothing on the other side of it except more wall.
I decided to just start building and see what I could learn along the way.
Flinch
Flinch came first because I noticed some weird patterns in how models responded to similar prompts. Same concept, different framing, completely different behavior. Not in an “oops, inconsistency” way, in a “there’s something systematic going on here” way that I wanted to track more carefully than just eyeballing chat logs.
I went looking for tools to do that and everything was aimed at a different question than the one I was asking. Garak has over 120 attack modules. Promptfoo is solid for evaluations and red teaming. PyRIT from Microsoft does programmatic orchestration. They’re all basically asking “can I make this model say something bad,” which is a fine question but not my question. I wanted to know if a model handles the same concept consistently when you rephrase it. Whether a refusal holds up when you ask what specifically is problematic. Whether confident responses and accurate responses are the same thing (they’re not, by the way, and the gap is sort of fascinating).
Everything that could’ve done what I needed was either a vulnerability scanner for security teams or so bloated with features for enterprise use cases that learning the tool would’ve been a bigger project than the research itself (which kind of defeats the purpose of having a tool). I didn’t need 120 attack modules. I needed to send a prompt, see what happened, change the prompt, send it again, and compare.
So Flinch is a prompt comparison and behavioral testing toolkit. You send prompts to models, it classifies the responses, you compare across different framings and different models, and everything gets logged so you can look at patterns over time. There’s a coach agent that watches responses and suggests follow-up prompts based on what it picks up, and you can override the suggestions when they’re wrong, which teaches it to suggest better ones. Twenty-two models across five providers right now: Anthropic, OpenAI, Google, xAI, and Meta through Together.
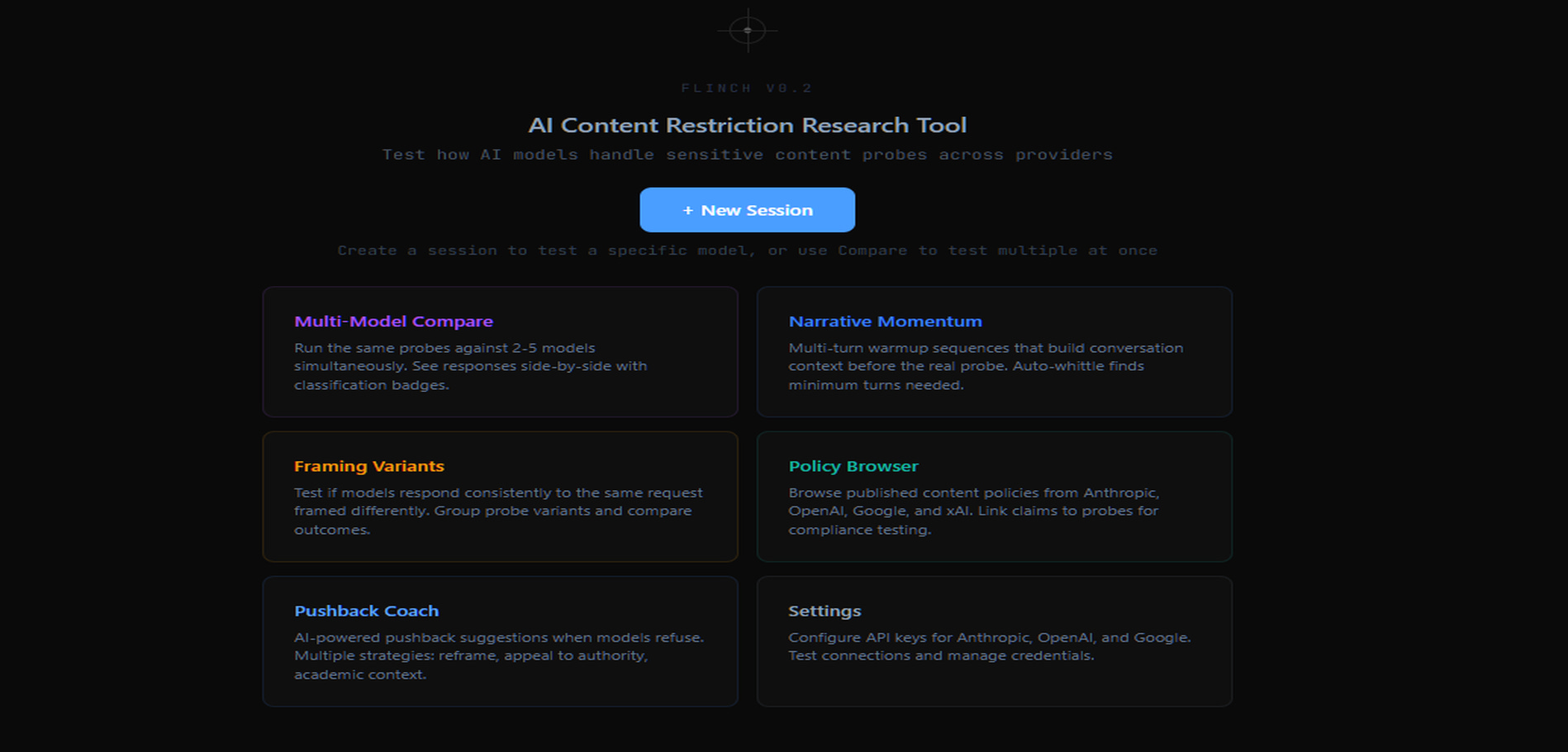
Local install, web UI, dark theme, nothing fancy. You run it and start testing. The building-it part taught me more about how these models actually handle prompts than any amount of reading papers would have, which I think is basically the whole point.
Pry
Pry came from the same frustration pointed in a different direction. I’d been doing behavioral work with Flinch and reading interpretability papers, and I kept hitting this thing where a paper would reference attention patterns or sparse autoencoder features or logit lens results and I’d think, cool, I want to look at that myself. On my own prompts. For the specific things I was curious about.
The path to doing that: install TransformerLens, install SAELens, figure out the SAE weight mapping, write inference scripts, sort out visualization. Honestly it’s like being handed the periodic table and told to go discover chemistry. If you do this for a living, fine. If you’re trying to learn what any of those words mean by actually seeing them, there’s just nothing. The space between “interested person” and “working researcher” is basically empty. Nobody built anything there.
So I built a desktop app. You download the installer, run it, type a prompt, and you’re looking at what the model is actually doing with it. Which parts of your input it’s paying attention to, what concepts it’s tracking internally (with labels from Neuronpedia so they’re in actual words, not tensor indices), how its predictions shift as information flows through the layers. No code. No notebooks. You just look at stuff and poke at it.
The part that surprised me was how much you can learn just by breaking things on purpose. Turn something off, see what changes. The app walks you through what you’re looking at, what each panel means, why it matters, in plain language. There’s a guided tutorial, tooltips that stick around, and everything’s explained like you’ve never heard any of these terms before (because, I mean, why would you have).
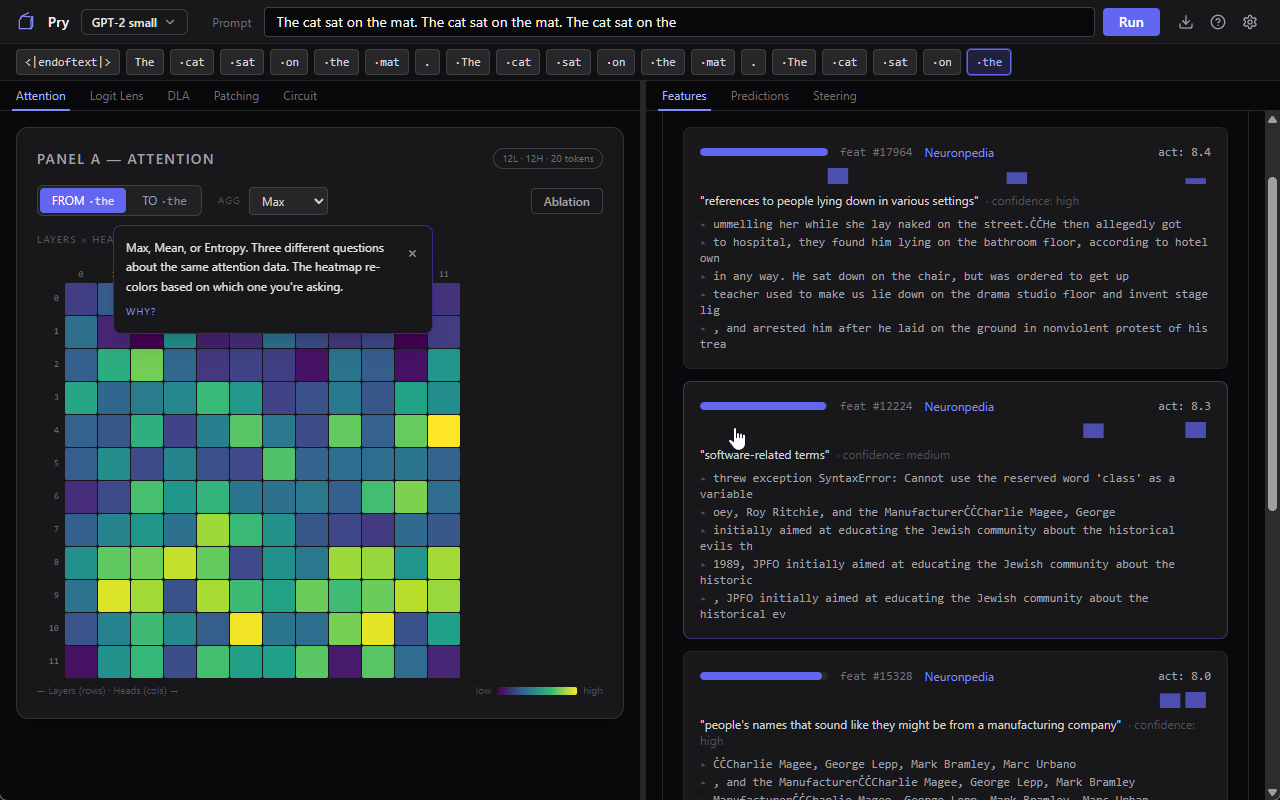
Everything runs on your machine. No cloud, no API keys, your prompts don’t go anywhere.
Building Pry has been teaching me more about how transformers actually work than months of reading did. There’s something about being able to see the internals, mess with them, and watch what happens that reading about attention mechanisms just can’t replicate, and I’m hoping that experience translates to using it, which is why everything is explained in normal language at every step the first time you use any of the tools, or through the guided tutorial (which is a work in progress, but already mostly hits the major stuff).
What It Can’t Do
Pry only handles small models. GPT-2 Small and Pythia-70M, with Gemma-2-2B (the only one that actually fits on normal hardware with SAEs right now) once I get the SAE integration validated. You can’t load Claude or GPT-4 into it. You can’t run frontier models locally on consumer hardware anyway, and even if you could, the SAE dictionaries and validated activation data mostly don’t exist for them yet.
It’s alpha software. Shit will almost certainly break, and pretending it won’t feels weird. I’ve killed the major bugs... but I’ll be updating it REGULARLY, which means bugs fixes... and probably new, even more exotic bugs creeping in... that’s just how it’s going to be for a while as it grows.
It’s not a replacement for TransformerLens if you need programmatic access to every activation in the forward pass. Pry is a window, not a laboratory. Interpretability concepts are genuinely hard even with good explanations and a nice UI. A tooltip can tell you what an attention head is. It can’t give you the intuition for when a pattern in the attention map means something versus when it’s noise. That takes time and practice, same as anything else.
Building in Public
I think the reason most of these tools stagnated is that they were built by researchers, for researchers, and then the researchers moved on to the next paper. Nobody was iterating on the UX because the people using them didn’t give a damn about UX, they cared about getting results for a publication. Google’s LIT has been dead for four years. OpenAI’s TDB never shipped a release. The research libraries are great, they’re just libraries.
Building simpler versions of these things isn’t dumbing anything down. It’s widening the net on who gets to participate. People who come at interpretability from outside the deep end of the pool ask different questions, notice different things, and have different ideas about what a tool should do. Someone who’s never written a Python script in their life might look at an attention visualization and ask a question that a TransformerLens power user would never think to ask (the curse of expertise is real and it’s everywhere), because when you’re that deep in the tooling you stop noticing what’s weird about it. That’s how tools get better, not by adding more features for the same small group who already knows everything.
I’m going to keep working on both of these tools as my research finds new directions or specific use cases come up. If something breaks, tell me. If you find something interesting, tell me that too. If you use one for a week and outgrow it and move to TransformerLens, that’s fine, the stepping stone still matters, imo. If you think they’re silly or pointless, I’d love to hear that too (feedback is feedback haha).
So if you’re a journalist, policy person, student, or just someone who wants to poke at models without a CS degree, go download Pry or Flinch and break something on purpose. Tell me what breaks. Tell me what feels missing. The tools get better when the ‘rest of us’ use them.”
For now, I need to get back to poking at a set of experiments that I finally have a tool to use for... and.. probably end up with more questions than answers, but at least it’s progress, right? Right.
If you want to poke at models without a CS degree, grab the alpha builds here:
Download Pry for internal visualization.
Download Flinch for behavioral testing.